Modeling is a very common term used in ML when you want to specify the steps taken to solve a particular problem. For example, you could create a binary classification model to predict whether the transactions from Table 1.1 are fraudulent or not.
A model, in this context, represents all the steps to create a solution as a whole, which includes (but is not limited to) the algorithm. The Cross-Industry Standard Process for Data Mining, more commonly referred to as CRISP-DM, is one of the methodologies that provides guidance on the common steps that you should follow to create models. This methodology is widely used by the market and is covered in the AWS Machine Learning Specialty exam:
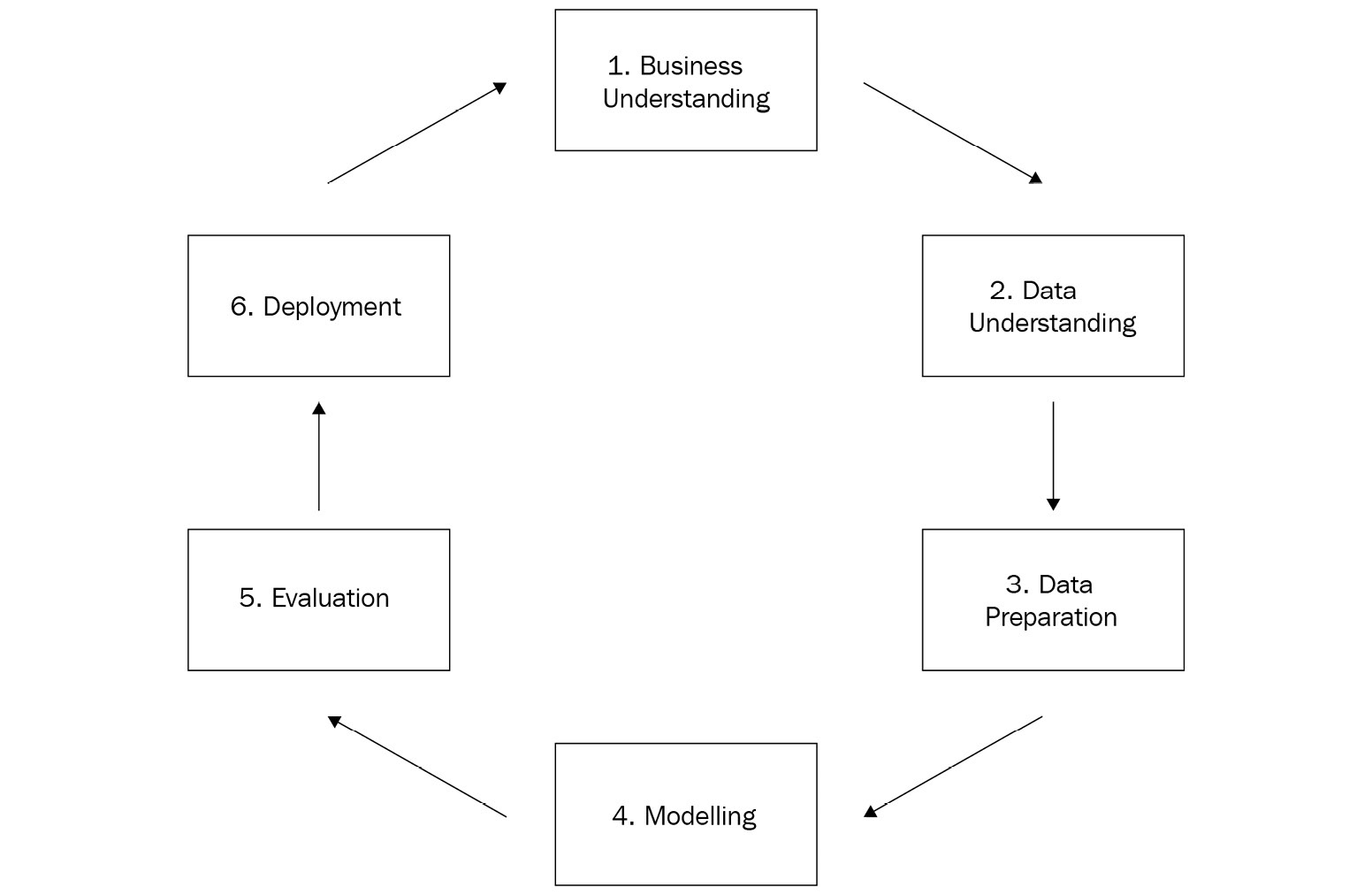
Figure 1.3 – CRISP-DM methodology
Everything starts with business understanding, which will produce the business objectives (including success criteria), situation assessment, data mining goals, and project plan (with an initial assessment of tools and techniques). During the situation assessment, you should also look into an inventory of resources, requirements, assumptions and constraints, risks, terminology, costs, and benefits. Every single assumption and success criterion matters when you are modeling.
The next step is known as data understanding, where you will collect raw data, describe it, explore it, and check its quality. This is an initial assessment of the data that will be used to create the model. Again, data scientists must be skeptical. You must be sure you understand all the nuances of the data and its source.
The data preparation phase is actually the one that usually consumes most of the time during modeling. In this phase, you need to select and filter the data, clean it according to the task that needs to be performed, come up with new attributes, integrate the data with other data sources, and format it as expected by the algorithm that will be applied. These tasks are often called feature engineering.
Once the data is prepared, you can finally start the modeling phase. Here is where the algorithms come in. You should start by ensuring the selection of the right technique. Remember: according to the presence or absence of a target variable (and its data type), you will have different algorithms to choose from. Each modeling technique might carry some implicit assumptions of which you have to be aware. For example, if you choose a multiple linear regression algorithm to predict house prices, you should be aware that this type of model expects a linear relationship between the variables of your data.
There are hundreds of algorithms out there and each of them might have its own assumptions. After choosing the ones that you want to test in your project, you should spend some time checking their specifics. In later chapters of this book, you will learn about some of them.
Important note
Some algorithms incorporate in their logic a sub-process known as feature selection. This is a step where the most important features will be selected to build your best model. Decision trees are examples of algorithms that perform feature selection automatically. You will learn about feature selection in more detail later on, since there are different ways to select the best variables for your model.
During the modeling phase, you should also design a testing approach for the model, defining which evaluation metrics will be used and how the data will be split. With that in place, you can finally build the model by setting the hyperparameters of the algorithm and feeding the model with data. This process of feeding the algorithm with data to find a good estimator is known as the training process. The data used to feed the model is known as training data. There are different ways to organize the training and testing data, which you will learn about in this chapter.
Important note
ML algorithms are built of parameters and hyperparameters. Parameters are learned from the data; for example: a decision-tree-based algorithm might learn from the training data that a particular feature should compose its root level based on information gain assessments. Hyperparameters, on the other hand, are used to control the learning process. Taking the same example about decision trees, you could specify the maximum allowed depth of the tree (regardless of the training data). Hyperparameter tuning is a very important topic in the exam and will be covered in fine-grained detail later on.
Once the model is trained, you can evaluate and review the results in order to propose the next steps. If the results are not acceptable (based on business success criteria), you should go back to earlier steps to check what else can be done to improve the model’s results. It could either be the subtle tuning of the hyperparameters of the algorithm, a new data preparation step, or even the redefinition of business drivers. On the other hand, if the model quality is acceptable, you can move on to the deployment phase.
In this last phase of the CRISP-DM methodology, you have to think about the deployment plan, monitoring, and maintenance of the model. You can look at this step from two perspectives: training and inference. The training pipeline consists of those steps needed to train the model, which include data preparation, hyperparameter definition, data splitting, and model training itself. Somehow, you must store all the model artifacts somewhere, since they will be used by the next pipeline that needs to be developed: the inference pipeline.
The inference pipeline just uses model artifacts to execute the model against brand-new observations (data that has never been seen by the model during the training phase). For example, if the model was trained to identify fraudulent transactions, this is the time when new transactions will pass through the model to be classified.
In general, models are trained once (through the training pipeline) and executed many times (through the inference pipeline). However, after some time, it is expected that there will be some model degradation, also known as model drift. This phenomenon happens because the model is usually trained in a static training set that aims to represent the business scenario at a given point in time; however, businesses evolve, and it might be necessary to retrain the model on more recent data to capture new business aspects. That’s why it is important to keep tracking model performance even after model deployment.
The CRISP-DM methodology is so important to the context of the AWS Machine Learning Specialty exam that, if you look at the four domains covered by AWS, you will realize that they were generalized from the CRISP-DM stages: data engineering, exploratory data analysis, modeling, and ML implementation and operations.
You now understand all the key stages of a modeling pipeline and you know that the algorithm itself is just part of a larger process! Next, you will see how to split your data to create and validate ML models.
Acedexam Training Policies
Learning resources
Other resources
Our Training Providers



