ExamAlert
Traditional RDS database read replicas are a very cost-efficient way to provide data for small (terabyte)-scale analytics and should be selected as a preferred option when the entire dataset needs to be read offloaded. Always evaluate whether the question requires you to offload a certain portion of the data (with caching) or the entire dataset is required (with read replicas).
Other AWS database services employ a decoupled compute–datastore approach. For example, the AWS Aurora service stores all the data on a cluster volume that is replicated to six copies across (at least) three availability zones. The primary instance has read and write access. All writes are sent as changelogs directly to the six nodes of the storage volume, and the commit to the database page is done at the storage cluster. This means that the replication is near synchronous with potentially no more than a few milliseconds of replication lag due to the network distance between the cluster volume nodes in other availability zones and several hundred milliseconds if the replication is done across regions. Additionally, Aurora supports up to 15 read replicas per region and can be deployed to multiple regions with an additional 16 read replicas in other regions. All of the read replicas read from the same cluster volume, meaning they can deliver near synchronous data for each read request. The read replicas can also be seamlessly scaled because there is no requirement to replicate the data on to the replica. When a replica is started, it is simply connected to the cluster volume. This allows the cluster to avoid initial replication lags that you would see in traditional databases. This feature can be used both for elasticity and vertical as well as horizontal scaling of the cluster. Figure 4.13 illustrates an Aurora cluster design.
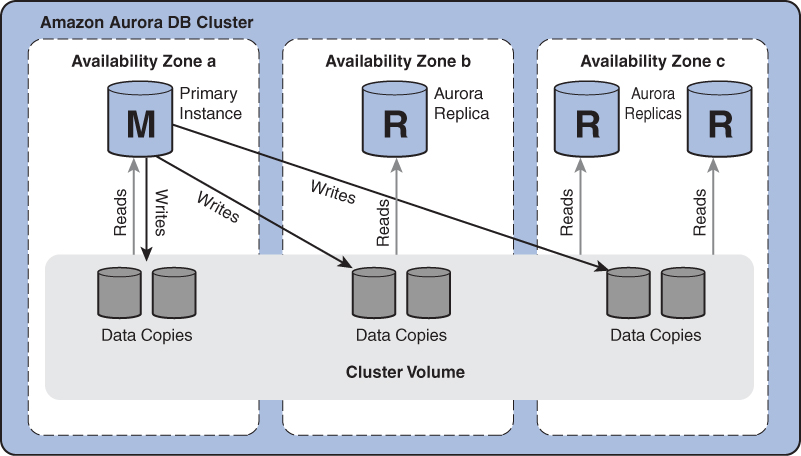
FIGURE 4.13 Aurora cluster design
A similar approach to decoupling the storage volume and the database nodes is used in DocumentDB, Neptune, and so on.
On top of this capability, Aurora can forward some read-heavy analytical operations to the cluster volume nodes and offload the primary from having to perform the reads for any JOIN, GROUP BY, UNION, and such operations across approximately a million or more rows. This capability extends the lightweight analytics capabilities of RDS read replicas to deliver much more power to your analytics queries.
Aurora natively supports MySQL and PostgreSQL databases and is slightly more expensive than RDS MySQL and RDS PostgreSQL.
ExamAlert
When an exam question indicates that high performance at high scale is required for MySQL or PostgreSQL, always evaluate whether the answer includes Aurora as an option. We recommend you select RDS MySQL or RDS PostgreSQL only if any cost considerations are explicitly stated in the question. Also, consider reducing the number of read replicas by powering them off or terminating them if they are not in use.
Acedexam Training Policies
Learning resources
Other resources
Our Training Providers



