ExamAlert
Remember, one of the crucial factors that enables scalability and elasticity is ensuring your resources are disposable. That means any data is always written outside the processing layer. All databases, files, logs, and any kind of output the application generates should always be decoupled from the processing layer. In the exam, different services might be part of the proposed solution. When analyzing the proposed answer, always ensure the data being output by the application doesn’t stay on the EC2 instance for a longer time and that the solution has the lowest cost. For example, one answer could propose that logs be sent to CloudWatch logs via the CloudWatch agent, whereas another answer might propose logs be written to S3 every hour. Although the second solution will probably be more cost-effective, you should consider the first solution if the defined SLA of the application requires that all logs need to be captured.
The general consensus is that there are only two ways (with minor variance, depending on the service or platform) to scale a service or an application:
Vertically, by adding more power (more CPU, memory, disk space, network bandwidth) to an application instance
Horizontally, by adding more instances to an application layer, thus increasing the power by a factor of the size of the instance added
A great benefit to vertical scaling is that it can be deployed in any circumstance, even without any application support. Because you are maintaining one unit and increasing its size, you can vertically scale to the maximum size of the unit in question. The maximum scaling size of an instance is defined by the maximum size that the service supports. For example, at the time of writing, the maximum instance size supported on EC2 (u-24tb1.metal) offers 448 CPU cores and 24 TB (that’s 24,576 GB!) of memory, while the smallest still-supported size (t2.nano) has only 1 CPU core and 0.5 GB of memory. Additionally, there are plenty of instance types and sizes to choose from, which means that you can horizontally scale an application the exact size you need at a certain moment in time. This same fact applies to other instance-based services such as EMR, RDS, and DocumentDB. Figure 4.1 illustrates vertical scaling of instances.
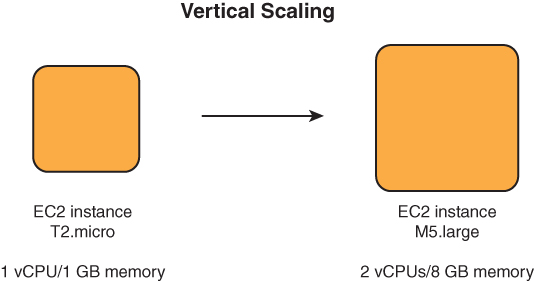
FIGURE 4.1 Vertical scaling
However, when thinking about scalability, you have to consider the drawbacks of vertical scaling. We mentioned maximum size, but one other major drawback is what makes horizontal scaling impractical—a single instance. Because all of AWS essentially operates on EC2 as the underlying design, you can take EC2 as a great example of why a single instance is not the way to go. Each instance you deploy is deployed on a hypervisor in a rack in a datacenter, and this datacenter can only ever be part of one availability zone. In Chapter 1, “Introduction to AWS,” we defined an availability zone as a fault isolation environment—meaning any failure, whether it is due to a power or network outage or even an earthquake or flood, is always isolated to one availability zone. Although a single instance is vertically scalable, it is by no means highly available, nor does the vertical scaling make the application very elastic, because every time you scale to a different instance type, you need to reboot the instance.
This is where horizontal scaling steps in. With horizontal scaling, you add more instances (scale-out) when traffic to your application increases and remove instances (scale-in) when traffic to your application is reduced. You still need to select the appropriate scaling step, which is, of course, defined by the instance size. When selecting the size of the instances in a scaling environment, always ensure that they can do the job and don’t waste resources. Figure 4.2 illustrates horizontal scaling.
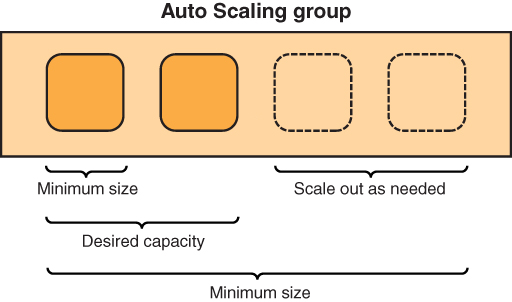
FIGURE 4.2 Horizontal scaling
In the ideal case, the application is stateless, meaning it does not store any data in the compute layer. In this case, you can easily scale the number of instances instead of scaling one instance up or down. The major benefit is that you can scale across multiple availability zones, thus inherently achieving high availability as well as elasticity. This is why the best practice on AWS is to create stateless, disposable instances and decouple the processing from the data and the layers of the application from each other. However, a potential drawback of horizontal scaling is when the application does not support it. The reality is that you will sooner or later come upon a case where you need to support an “enterprise” application, being migrated from some virtualized infrastructure, that simply does not support adding multiple instances to the mix. In this case you can still use the services within AWS to make the application highly available and recover it automatically in case of a failure. For such instances you can now utilize the AWS EC2 Auto Recovery service, for the instance types that support it, which automatically re-creates the instance in case of an underlying system impairment or failure.
Another potential issue that can prevent horizontal scalability is the requirement to store some data in a stateful manner. Thus far, we have said that you need to decouple the state of the application from the compute layer and store it in a back-end service—for example, a database or in-memory service. However, the scalability is ultimately limited by your ability to scale those back-end services that store the data. In the case of the Relational Database Service (RDS), you are always limited to one primary instance that handles all writes because both the data and metadata within a traditional database need to be consistent at all times. You can scale the primary instance vertically; however, there is a maximum limit the database service will support, as Figure 4.3 illustrates.
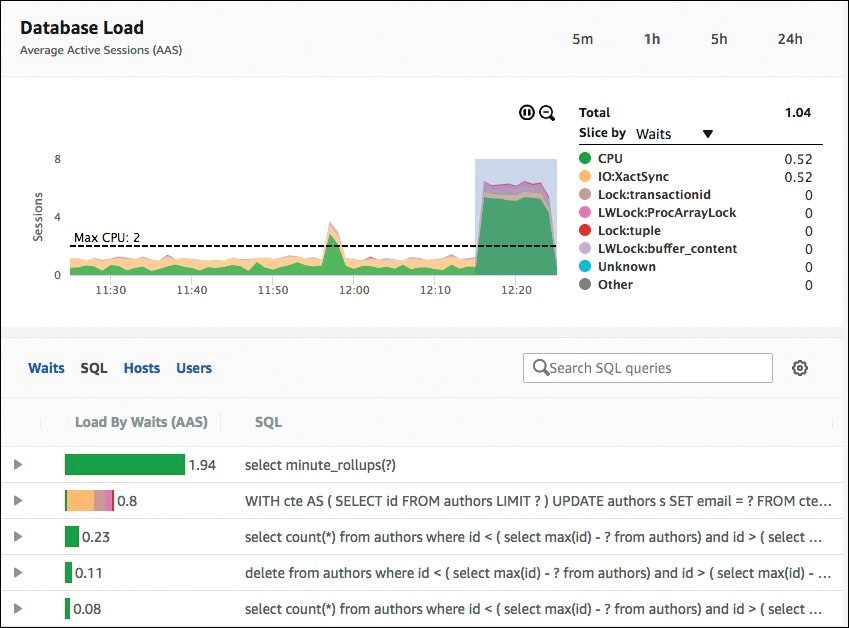
FIGURE 4.3 Database bottlenecking the application
You can also create a Multi-AZ deployment, which creates a secondary, synchronous replica of the primary database in another availability zone; however, Multi-AZ does not make the application more scalable because the replica is inaccessible to any SQL operations and is provided for the sole purpose of high availability. Another option is adding read replicas to the primary instance to offload read requests. We delve into more details on read replicas later in this chapter and discuss database high availability in Chapter 5.
ExamAlert
If the exam question is ambiguous about scalability or elasticity, you should still consider these as an important requirement of the application. Unless specific wording indicates cost as the primary or only driver, always choose the answer with the solution that will scale and is designed with elastic best practices in mind.
Acedexam Training Policies
Learning resources
Other resources
Our Training Providers



