Backup Frequency
How can you determine the optimal backup frequency? Provided that backup and restore can satisfy your RTO, the optimal backup frequency is the one that allows you to satisfy your RPO. The RPO will define how much data you are allowed to lose in case of a disaster. So, you need to make sure that the frequency at which you back up your workload will allow you enough time to do the backup and to store it safely where you can use it to recover. If you plan to recover in a separate AWS Region, you need to allow enough time for the backup data to safely reach that second Region. To give a concrete example, if your RPO is 2 hours, you want your backup frequency to be less than that. In fact, you may want to be on the safe side and plan for a potentially missed backup just in case (better safe than sorry). Therefore, you may want to set an hourly backup frequency. This way, if one of the hourly backups fails, you still have time to respond automatically, or even manually in the worst case. You could wait for the next automated hourly backup to be triggered and validate it goes well or otherwise make a backup manually.
The pilot light approach consists of maintaining a copy of your data in a secondary region and your workload infrastructure in a pre-provisioned but switched-off mode, so all the necessary storage is already present, as well as the data stores (for instance, RDS read replicas), but all the compute is switched off, except when necessary to support the data replication (for instance, again, RDS read replicas). Any other compute is off, so no EC2 instances are running (other than for supporting data stores replication), no Amazon Elastic Container Service (ECS) cluster tasks are running, and no Amazon Elastic Kubernetes Service (EKS) cluster Pods are running.
The overall idea behind the pilot light approach is that you are almost ready to handle incoming requests and get your workload up and running in that secondary region, but you maintain a reduced footprint by having no running compute. This approach is illustrated in the following diagram:
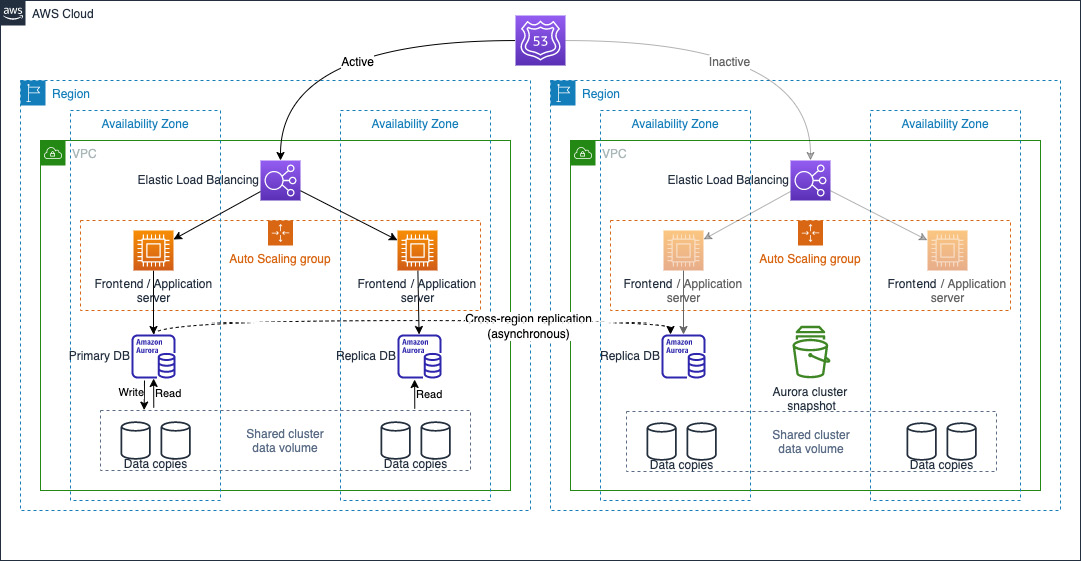
Figure 7.3: Pilot light approach
This approach is valid when your RTO is low enough so that a backup and recovery strategy will not be a good fit, but not so low that you do not get enough time to get everything up and running. This is typically a good fit when your RTO is in the tens of minutes range.
Compared to backup and recovery, because your core infrastructure is already in place and all you need to do is to get the compute capacity up and running, it is easier to test and validate that your DR plan is fully functional.
Acedexam Training Policies
Learning resources
Other resources
Our Training Providers



